
Аудитория приносит сайту доход. Чем больше людей посещают ваш ресурс и кликают по рекламе, тем больше денег вы получаете. В связи с этим важно анализировать посетителей: сколько им лет, как они находят сайт, с каких сайтов переходят к вам. На основе этих данных можно скорректировать собственные методики продвижения. То же касается и чужих ресурсов.
Можно извлечь их статистику и использовать ради собственной выгоды.
Далее выясним, как узнать, откуда идет трафик на сайт конкурентов, и как посмотреть статистику посещаемости своего проекта. Какие сервисы лучше остальных подходят для решения этих задач и как они работают.
Откуда идет трафик на наш сайт?
Для начала выясним, как получить аналитику по своему сайту.
Яндекс.Метрика
В РФ любят Яндекс.Метрику и частенько используют только ее. Главное в этой аналитической системе — простота. Интерфейс логичный и понятный. Вся информация подается наглядно, чтобы даже несведущий пользователь понял, что ему пытаются донести.
- Количество посетителей.
- Возрасти и пол аудитории.
- Источники новых и постоянных посетителей.
- По каким поисковым запросам находят страницу.
- Как часто пользователи уходят с сайта, посмотрев всего одну страницу.
- С каких устройств люди заходят на сайт.
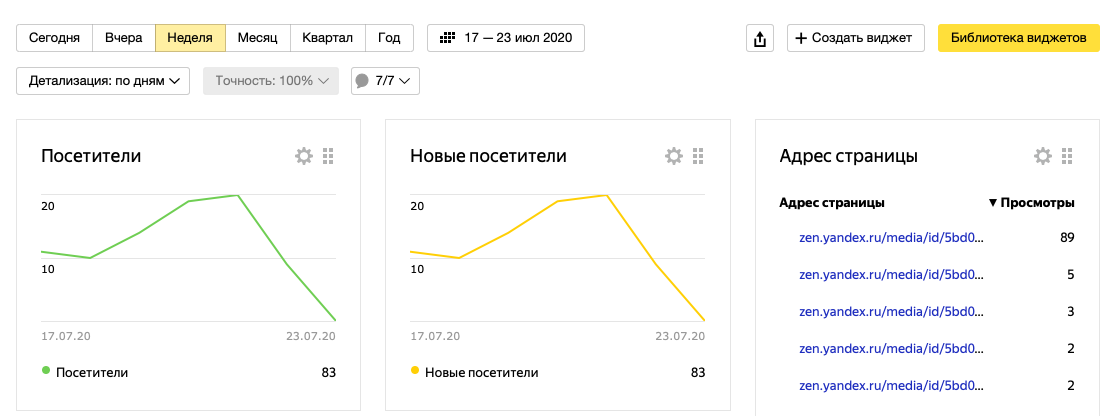
А еще там есть «Вебвизор». Раздел аналитики, который визуально показывает, на каких страницах сайта чаще всего бывают пользователи, куда они чаще кликают, где удерживают курсор, как далеко скроллят. В общем, дает возможность оказаться в шкуре среднестатистического посетителя вашего ресурса.
Из плюсов Метрики можно также выделить установку целей по количеству посетителей и других показателей для более удобного отслеживания.
Подключить Яндекс.Метрику легко. Надо встроить код с сайта Яндекса в код вашего сайта. Либо воспользоваться специальным плагином для используемой CMS. Например, есть одноименный плагин для WordPress, который принимает коды с Метрики.
Google Analytics
Та же Метрика, только от команды разработчиков Google и более прокачанная. Эта система постарше и использует иные алгоритмы. Считается неким стандартом среди веб-мастеров и SEO-шников. Google Analytics полезна тем, что помогает составить представление как о посещаемости, так и о потенциальном доходе сайта.
Из преимуществ стоит выделить:
- Большой объем информации с каким-то запредельным набором фильтров для поиска конкретных данных в заданной выборке.
- Доступ к информации касаемо оборота в интернет-магазинах. Можно отыскать информацию о количестве заказов и людях, их сделавших.
- Резервное копирование данных на тот случай, если система выйдет из строя. Вся аналитика сохранится при любых обстоятельствах.
- Несложная интеграция с аналитическими инструментами сторонних компаний и прочими приложениями.
Минусами этой системы считают трудности в обслуживании. Чтобы воспользоваться всеми предложенными аналитическими инструментами Google Analytics, придется заручиться не только помощью вебмастеров, но и разработчиков. А еще Google показывает не все ключи, по которым визитеры находят анализируемую страницу в поисковике.
LiveInternet
Один из старейших представителей аналитических систем. Система была популярна в прошлом, когда не было серьезной конкуренции со стороны Метрики и Google Analytics в России. Вы наверняка видели счетчики LiveInternet раньше. Это оранжевые блоки со статистикой в «подвале» страницы.
Установка счетчика LiveInternet почти не отличается от такой в Метрике: надо зарегистрироваться и получить HTML-код для интеграции в свой сайт.

Количество и характер информации в этой аналитической системе тоже близок к информации у конкурентов. Правда, подается она не так наглядно. Естественно, сложных механизмов аналитики (например, «Вебвизора») тут нет. Ну и визуальная составляющая далека от симпатичной.
Наверное, имея доступ к Метрике и Google Analytics, можно обойтись без LiveInternet. С другой стороны, чем больше информации из разных источников, тем лучше.


Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Анализ посещаемости чужого сайта
Анализ собственной аудитории и статистики ресурса — часть формирования бизнес-стратегии. Но изучение конкурентов также важно (если не важнее). Информация о похожих сайтах иногда приносит даже больше пользы и помогает выбрать иной путь развития, более выгодный в долгосрочной перспективе.
Для этого есть несколько инструментов, похожих на описанные выше, но с ограниченным набором данных (по объективным причинам).
SimilarWeb
Любимец SEO-шников и рекламистов. Один из фаворитов команды Adv-Cake, занимающейся контекстной рекламой. Его прелесть в обилии полезной информации о ресурсах других компаний. Можно узнать, как много уникальных посетителей посещают сайт ежемесячно. Как много страниц они просматривают, сколько времени проводят на сайте.
Здесь отображаются даже некоторые инструменты, которые используют разработчики анализируемого ресурса.
Используя даже бесплатные данные из SimilarWeb, можно оценить приблизительную прибыль проекта. Для этого есть специальная формула: количество баннеров * стоимость рекламы * количество посетителей * количество страниц, на которые заходили пользователи
Понятное дело, баннер ы — не единственный источник дохода для больших проектов, но эти данные все еще могут оказаться полезными.
Еще SimilarWeb может поведать о том, чьими услугами пользуется анализируемый веб-сайт. Откуда берет трафик. Какие адекватные источники трафика есть у ресурса. На основе этой информации можно несколько скорректировать собственную рекламную кампанию.
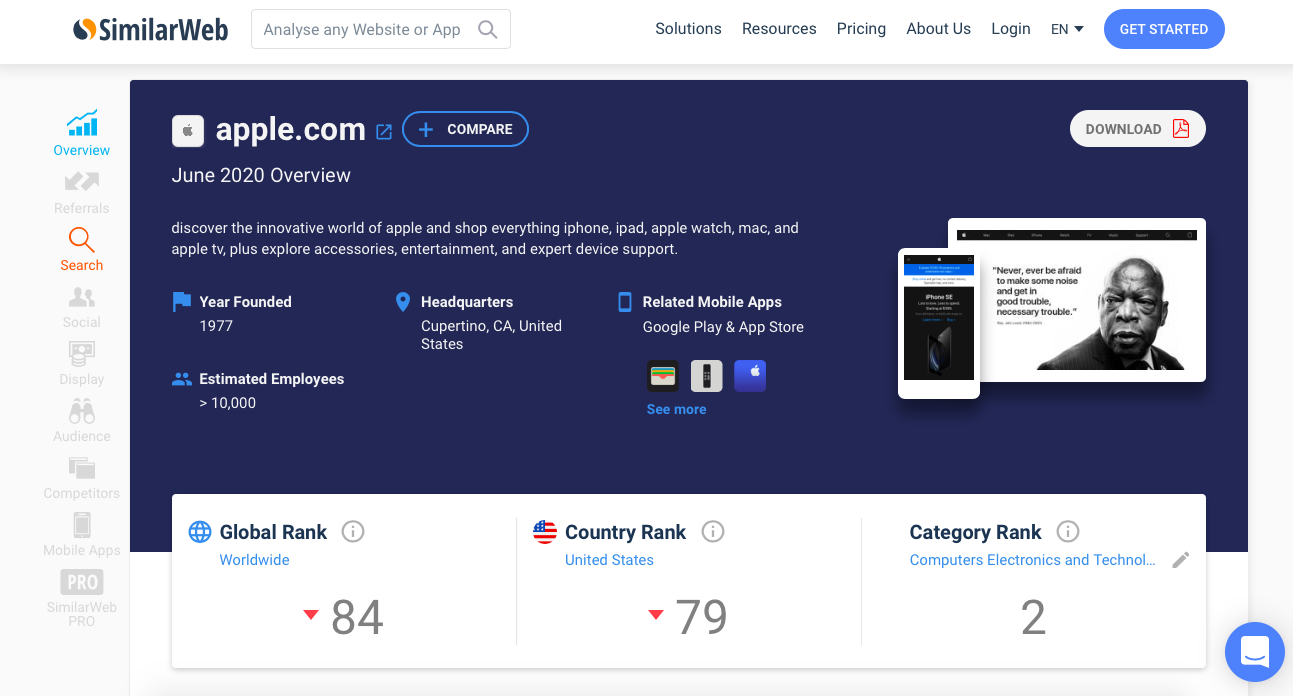
В платной версии SimilarWeb информации гораздо больше. Там есть:
- Ключи, по которым люди попадают на сайт из поисковиков.
- Запросы из контекстных объявлений.
- Сами контекстные объявления.
- Используемые на сайтах баннеры.
- Субдомены и лендинги партнеров.
Получаем мощнейший инструмент для анализа конкурентов с возможностью до мельчайшей крупицы воспроизвести рекламную кампанию любой страницы в интернете. Остается только заплатить.
SEMrush
Копия предыдущего сервиса. Сказать о нем нечего. Он делает все те же вещи, что и SimilarWeb. Они отличаются стоимостью и функциональностью между платным и бесплатными тарифами. Видят разное количество информации о разных сайтах. Поэтому назвать их взаимозаменяемыми не получится.
Количество данных может отличаться. Иногда заметно.
Если преследуете серьезные цели относительно аналитики, я бы рекомендовал обратить внимание на оба сервиса. В тандеме они дадут безумный объем данных, на основе которых можно будет построить действенную рекламную кампанию уровня «взрослых» проектов или даже лучше.
SEMrush стоит дешевле. Это одна из причин, по которой ему иногда отдают предпочтение. Но SimilarWeb берет своим именем и репутацией.
Advse
Продукт для извлечения поисковых запросов из контекстной рекламы сайта. Рекламисты его любят, но советуют не злоупотреблять. По мнению профессионалов из Adv-Cake, лучше ознакомиться с ключами конкурентов, но не копировать их бездумно. Тут как никогда важно критическое мышление. Иначе есть шанс сократить полезность действующей рекламной кампании.
Другие способы
SimilarWeb, SEMrush и Advse имеют один и тот же недостаток. Они полезны только при условии, что запрашиваемые данные относятся к большому проекту. Они дадут кучу данных по условной ЛаМоде, но ничего не поведают о каком-нибудь узкоспециализированном маленьком ресурсе (потенциальном конкуренте).
Тут может помочь счетчик LiveInternet. Если видите в футере сайта оранжевый блок со статистикой LiveInternet:
- Кликаем по блоку со статистикой.
- Оказавшись на сайте с аналитикой, кликаем по позиции сайта в общем рейтинге.
- Ищем рядом с нужным сайтом любой с открытыми данными и выбираем его.
Данные будут приблизительно такими же, как у сайта, который мы хотели проанализировать.
Есть еще один метод получить чуть больше полезной информации о проекте. Для этого надо ввести в адресную строку браузера ссылку типа http://counter.yadro.ru/values?site=адрес сайта, в который хочется залезть . Не всегда работает, но когда работает, показывает чуть больше данных, включая количество посещений.
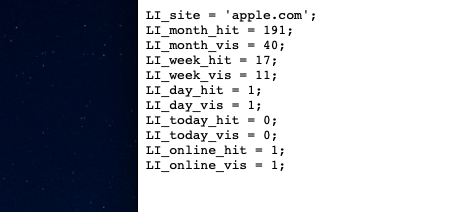
На этом все. Способов собрать аналитику посещаемости и каналов трафика много, но я перечислил наиболее востребованные и толковые. Их хватит, чтобы получить все нужные данные для формирования адекватной стратегии развития.
Источник: timeweb.com
Новый алгоритм Яндекса YATI — что это такое и как работает
Говорят, что Яндекс YATI — подарок для сеошников, продвигающих ресурсы по-белому. В ТОП якобы стало возможно выходить даже по ВЧ-запросам. Попробуем выяснить, так ли это на самом деле, и насколько алгоритм изменил правила ранжирования в 2021 году.
Наши друзья из ProTraffic рассказывают о новом поисковом алгоритме.
Что представляет собой новый алгоритм Яндекса YATI
Дата выхода YATI — скорее всего, конец сентября 2020 года, а не 11 месяц года, как считают обычно. В ноябре как раз не было шторма позиций, присущих анонсированию нового алгоритма — обычно должен происходить фундаментальный апдейт (Core Updates), затрагивающий большую долю поисковых запросов. У Яндекса последний излом был как раз 25 сентября.

Новый трансформер учитывает смысловую составляющую, обеспечивая совершенно другой уровень в ранжировании. Его действие основано на работе нейросетей-трансформеров или моделей машинного обучения. Сама идея перенята от Google Brain в 2017 году, внедрена в российский поиск с полезными доработками.
Пока нейросеть в Yandex — не единственный звеновой, так как влияет на сортировку сайтов вкупе с другими не менее важными SEO-факторами: поведенческими, хостовыми, ссылочными. Таким образом, выдача у нас получается смешанная.

Получаем очень важный вывод, характеризующий новый алгоритм. С его выходом впервые факторы «смысла» нередко оказываются сильнее SEO-критериев, по которым оценивались сайты прежде.
Еще по теме:
Как попасть в колдунщики Яндекса и получить больше трафика
Вот другой пример, где работал только YATI. Все представленные документы определены по смыслу:

Но происходит это пока по низкочастотным и среднечастотным запросам. Хотя встречаются веб-мастера, утверждающие, что их ресурс повысился в SERP и по ВЧ, после того, как они доработали его под требования YATI.

Зачем внедрили YATI
Цель — повысить способность роботов находить релевантный ответ на вопрос пользователя. Алгоритм призван лучше оценивать смысловую близость запроса и документа (веб-страницы), почти как человек.
А что тогда было до этого? До 2016 года поисковая машина Yandex учитывала только 5-10% всего текста, остальной материал просто игнорировался. Конечно, были определенные попытки: продвинутая языковая модель, латентно-семантическое индексирование (LSA) и т. д. Но фактически ПС читала поверхностно, понимала только заголовок, вхождение ключевых слов, некоторые синонимы главного запроса и общепринятые термины.
Такая ситуация и послужила толчком к внедрению более умного робота. По заверениям специалистов Яндекса, YATI свою задачу выполнил на 96% — ранжирование улучшилось значительно, по сравнению с тем, что было за последние 10 лет.
Яндекс не сразу эволюционировал. До этого были две попытки ввода нейросетевого поиска:
- сначала был Палех (2016) — умел понимать запрос и заголовок, используя для этого буквенные триграммы и биграммы слов, но все это только для 150 топовых страниц (другими словами, работал только с первой десяткой выдачи плюс 5 сайтов);
- затем Королев (2017) — использовал стримы и был способен учитывать не только тайтл и ключевую фразу, но и сам контент (правда, лишь отдельные важные отрывки) для 200 тыс. документов.
И наконец, новая архитектура или новая технология анализа текста, которая модернизировала поиск лучше, чем Палех и Королев вместе взятые. С YATI стало возможно использовать еще больше стримов — анкор-лист, запросный индекс для урлов по кликам — и понимать статьи до 10 предложений целиком, без разбивки на отдельные фрагменты.

После внедрения трансформеров поиск может не просто работать с запросами (заголовками), но и оценивать большие документы, выделяя в них значимые, важные фрагменты. А также распознавать опечатки, учитывать порядок слов, их влияние друг на друга и многое другое.
Для YATI Яндекс реально усложнил задачу. Трансформеру не просто показывали неструктурированные тексты для анализа, как это делается классически, а предлагали реальные ключи и документы, которые видели пользователи. Робот должен был угадать, какой материал понравится пользователям и асессорам больше/меньше. Таким образом, машина обучается ранжировать и гораздо лучше понимает, насколько контент релевантен вопросу.
Что круче: YATI или BERT?
Яндекс утверждает, что YATI — это доработанный вариант BERT, и у него получается лучше понимать запросы пользователей. Так ли это на самом деле или просто попытка выделиться на фоне конкурента? В отечественном поиске может быть, так как буржуйские алгоритмы никогда не отличались любовью к русской грамматике и часто ошибались.
Но в глобальном смысле западная машина, скорее всего, круче. Это многослойная нейронка, способная помимо всего прочего разделять запросы/ответы, искать сущность вопроса и смысловую близость, а также многое другое. И это несмотря на то, что широко принятая метрика оценки качества выдачи (nDCG) отдает предпочтение YATI.
Требования YATI – как подготовить сайт
У некоторых веб-мастеров страницы поползли вверх, стоило им только несколько изменить правила, сделав материалы более соответствующими YATI. 3 правила связаны с главным ключевым запросом, по которому продвигается документ.

- Точное вхождение. Важно для низкочастотных фраз, особенно хорошо заметно на коммерческих сайтах (на информационных ресурсах явного влияния в Топ-10 нет, зато есть вне его). Чтобы убедиться в том, что нейронка больше уделяет этому внимания, чем раньше — достаточно сравнить показатели по значимости данного фактора до и после запуска YATI. А вот со средне- и высокочастотными ключами подобной тенденции не наблюдается, и можно добавлять слова в неточном вхождении, и даже синонимы.
2. Все слова из запроса. Работает также хорошо, как и раньше. При этом не имеет значения, к какой именно частотности относится фраза. Правило действует одинаково эффективно для НЧ, СЧ и ВЧ.
3. Вхождение в title, H1, H2. С трансформером это требование больше работает с низкочастотниками. Не менее важно добавлять тематические слова.
Другие требования по статьям:

- максимизировать в тексте количество слов из подсветки выдачи, а еще использовать больше фраз, задающих тематику и встречающихся у конкурентов в топе, даже при их отсутствии в поисковом запросе; Слова из подсветки Яндекса по словосочетанию «пластиковые окна»

- применять форматирование, особенно в больших материалах — другими словами, разбивать статью на части с подзаголовками (на каждые 12-14 предложений), использовать списки, цитаты и т. д;
- анализировать запросы, по которым было много переходов на URL — если они не релевантны контенту, то внести соответствующие изменения в статью;
- расширить семантику в сторону НЧ — включать больше синонимов, а вообще для YATI в приоритете неоднозначные, многословные и редкие фразы (длинный хвост);
- проводить анализ конкурентов — стараться делать свой материал более развернутым чем у оппонентов, полнее раскрывать запрос;
- изучить и при необходимости перегруппировать (освежить) семантическое ядро, если это не было сделано за последние 4-6 месяца (особенно актуально для коммерческих сайтов, интернет-магазинов) — ряд запросов могли поменять свой тип, стать целевыми или наоборот.
Так есть ли принципиально новые изменения?
Не стоит забывать, что YATI лишь на 50% сортирует ТОП выдачи. Главную роль в ранжировании по-прежнему играют эти факторы:
- ИКС;
- общее количество страниц ресурса;
- структура;
- качество и уникальность контента;
- ссылочный профиль;
- число посетителей (трафик);
- ПФ.
Многие специалисты как раз рекомендуют работать в 2021 году над улучшением поведенческих факторов. Разумеется, без откровенной накрутки, поскольку еще в прошлом году, до запуска YATI, российский поисковик скосил большое количество сайтов за неестественность ПФ.

А что по ВЧ?
На форумах часто спорят: легко ли сейчас продвинуться с качественным контентом по ВЧ. Одни пишут, что это невозможно, так как Яндекс уготовил места под ТОП для рекламы и ресурсов со спец разрешением. Другие считают иначе. Мы проверили ТОП-5 по высокочастотным запросам разной тематики. И вот что получилось:
- «продвижение сайтов» — 1-2 места спецразмещение и Дзен, 3 и 5 места за информационными веб-ресурсами;

- «как бросить курить» — 1-2 места тоже заняты, на этот раз включился Яндекс Кью;

- «мебель своими руками», «самая быстрая машина» — большое количество хороших сайтов.
Как видим, даже с ВЧ-запросом можно продвинуться на первые позиции, стоит лишь грамотно подготовить контент.
Заключение
Таким образом, новый алгоритм поднял качество машинного поиска на новый, более высокий уровень. Хорошо виден прогресс искусственного интеллекта в сторону естественности — нейронные сети трансформеры, почти как люди, способны оценивать текст. При всем этом SEO-шникам не стоит забывать про классику оптимизации. Все что имело значение раньше, никуда не делось. Просто YATI внес дополнительные улучшения, и по сути — никакой революции не произошло.
С другой стороны, выдача безусловно изменится — повысятся требования к качеству контента. Поэтому уже сейчас надо вносить полезные изменения на сайте, обновлять и дорабатывать старые статьи, добавлять новые материалы. Все это требует регулярного анализа (мониторинга), а помогут в этом веб-мастеру специальные сервисы, такие как Анализ сайта от PR-CY.
FAQ
- С какого года в российском поиске используется машинное обучение? Яндекс внедрил эту технологию частично еще с 2009 года, когда представил алгоритм Снежинск (запатентованный Matrix Next). После 2016 ввели Палех, Королев и Yati (последний на данный момент).
- С какого года использует нейросети Google? В 2013 word2vec, 2019 — BERT.
- Как обучают YATI? По нескольким фичам: оценкам толокеров и асессоров, предварительным обучением на клик, отдельно собранным данным (точный запрос, синонимы, выборочные фрагменты/идеал, стримы).
- Традиционная Seo-оптимизация текстов с внедрением последней нейронной сети стала неактуальной? Нет, это не так. Базовые принципы ранжирования остались, просто теперь больше внимания будет уделено смысловой близости запроса и документа.
- Что означает слово «трансформер»? В этом случае сравнительно умная нейросеть с мощнейшим вычислительным потенциалом, которая умеет быстро справляться с различными задачами в области анализа языковых конструкций.
- Чем Yati принципиально отличается от Палеха и Королева? Стало еще больше стримов, и понимание машиной контента страницы достигло высшего уровня на данный момент. Робот теперь понимает короткие статьи (до 10 предложений), и только большие материалы разбивает на отдельные фрагменты.
- Какой сайт больше подойдет под YATI? Скорее всего, который сделал упор на разнообразие. Мнение, что новый алгоритм будет лояльнее относиться к крупным проектам, не подтверждается. Главное — качество и полное раскрытие темы.
- Стоит ли заморачиваться с требованиями под Яндекс, если все равно топ выдачи уготован под собственные проекты (колдунщики)? Конечно же, это не так. Достаточно проверить SERP по высокочастотным запросам разной тематики — сервисы Yandex встречаются там лишь на 5%, остальные 95% трафика чиста.
Расскажите в комментариях, что поменялось у вас после введения YATI? Стало лучше или хуже?
Источник: pr-cy.ru