Карл Фридрих Гаусс был вундеркиндом и блестящим математиком, жившим с конца 18-го по середину 19-го века. Вклад Гаусса включал квадратные уравнения, анализ методом наименьших квадратов и нормальное распределение. Хотя нормальное распределение было известно из работ Абрахама де Муавра еще в середине 1700-х годов, заслугу в открытии часто ставят Гауссу, а нормальное распределение часто называют распределением Гаусса.
422 показа
268 открытий
Большая часть исследований статистики была основана Гауссом, и его модели применяются к финансовым рынкам, ценам и вероятностям. Современная терминология определяет нормальное распределение как колоколообразную кривую со средним значением и параметрами дисперсии. В этой статье объясняется колоколообразная кривая и применяется эта концепция к торговле.
Центр измерения: Среднее значение, медиана и режим
Показатели центра распределения включают среднее значение, медиану и режим. Среднее значение, которое является просто средним показателем, получается путем сложения всех баллов и деления на количество баллов. Медиана получается путем сложения двух средних чисел упорядоченной выборки и деления на два (в случае четного числа значений данных) или просто взятия среднего значения (в случае нечетного числа значений данных). Режим — это наиболее часто встречающееся число в распределении значений.
ОСНОВНЫЕ ВЫВОДЫ
- Гауссово распределение — это статистическая концепция, которая также известна как нормальное распределение.
- Для данного набора данных нормальное распределение помещает среднее значение (или усредненную величину) в центр, а стандартные отклонения измеряют дисперсию вокруг среднего значения.
- При нормальном распределении 68% всех данных находятся в пределах от -1 до +1 стандартного отклонения от среднего значения, 95% находятся в пределах двух стандартных отклонений и 99,7% находятся в пределах трех стандартных отклонений.
- Инвестиции с высокими стандартными отклонениями считаются более рискованными по сравнению с инвестициями с низкими стандартными отклонениями.
Теоретически медиана, режим и среднее значение идентичны для нормального распределения. Однако при использовании данных среднее значение является предпочтительным измерением центра среди этих трех. Если значения соответствуют нормальному (гауссову) распределению, 68% всех оценок находятся в пределах -1 и +1 стандартных отклонений (от среднего значения), 95% находятся в пределах двух стандартных отклонений и 99,7% находятся в пределах трех стандартных отклонений. Стандартное отклонение — это квадратный корень из дисперсии, который измеряет разброс распределения.
Гауссова модель для трейдинга
Стандартное отклонение измеряет волатильность и определяет, каких показателей доходности можно ожидать. Меньшие стандартные отклонения подразумевают меньший риск для инвестиций, в то время как более высокие стандартные отклонения подразумевают более высокий риск. Трейдеры могут измерять цены закрытия как разницу от среднего значения; большая разница между фактическим значением и средним значением предполагает более высокое стандартное отклонение и, следовательно, большую волатильность.
Цены, которые сильно отклоняются от среднего значения, могут вернуться обратно к среднему значению, так что трейдеры могут воспользоваться этими ситуациями, а цены, которые торгуются в небольшом диапазоне, могут быть готовы к прорыву. Часто используемым техническим индикатором для сделок со стандартным отклонением являются линии Боллинджера, поскольку это показатель волатильности, установленный на уровне двух стандартных отклонений для верхней и нижней полос с 21-дневной скользящей средней.
Перекос и эксцесс
Данные обычно не соответствуют точной форме колоколообразной кривой нормального распределения. Перекос и эксцесс — это показатели того, насколько данные отклоняются от этого идеального шаблона. Перекос измеряет асимметрию хвостов распределения: при положительном перекосе данные отклоняются больше в сторону увеличения среднего значения, чем в сторону уменьшения; обратное верно для отрицательного перекоса.
В то время как перекос связан с дисбалансом хвостов, эксцесс связан с конечностями хвостов независимо от того, находятся ли они выше или ниже среднего значения. Лептокуртическое распределение имеет положительный избыточный эксцесс и имеет значения данных, которые являются более экстремальными (в любом хвосте), чем предсказывается нормальным распределением (например, пять или более стандартных отклонений от среднего значения). Отрицательный избыточный эксцесс, называемый платикуртозом, характеризуется распределением с характером экстремальных значений, которое является менее экстремальным, чем у нормального распределения.
В качестве применения перекоса и эксцесса анализ ценных бумаг с фиксированным доходом, например, требует тщательного статистического анализа для определения волатильности портфеля при изменении процентных ставок. Модели, которые предсказывают направление движения, должны учитывать перекос и эксцесс для прогнозирования доходности портфеля облигаций. Эти статистические концепции могут быть в дальнейшем применены для определения динамики цен на многие другие финансовые инструменты, такие как акции, опционы и валютные пары.
Расчет волатильности: Упрощенный подход
Многие инвесторы сталкивались с аномальными уровнями волатильности инвестиционных показателей в различные периоды рыночного цикла. Хотя временами волатильность может быть выше, чем ожидалось, можно также привести доводы в пользу того, что способ, которым обычно измеряется волатильность, усугубляет проблему, связанную с тем, что акции кажутся неожиданно, необъяснимо волатильными.
Дальше обсудим вопросы, связанные с традиционным показателем волатильности, и рассмотрим более интуитивный подход, который инвесторы могут использовать, чтобы помочь себе оценить величину рисков.
Традиционный показатель волатильности
Большинство инвесторов знают, что стандартное отклонение — это типичная статистика, используемая для измерения волатильности. Стандартное отклонение просто определяется как квадратный корень из среднего отклонения данных от их среднего значения.
Хотя эту статистику относительно легко рассчитать, предположения, лежащие в основе ее интерпретации, сложнее, что, в свою очередь, вызывает обеспокоенность по поводу ее точности. В результате существует определенный уровень скептицизма в отношении его достоверности как точного показателя риска.
Для того чтобы стандартное отклонение было точной мерой риска, необходимо сделать предположение о том, что данные об эффективности инвестиций соответствуют нормальному распределению. В графическом выражении нормальное распределение данных будет отображаться на диаграмме в виде колоколообразной кривой. Если этот стандарт верен, то приблизительно 68% ожидаемых результатов должны находиться в пределах ±1 стандартного отклонения от ожидаемой доходности инвестиций, 95% должны находиться в пределах ± 2 стандартных отклонений и 99,7% должны находиться в пределах ± 3 стандартных отклонений.
Например, с 1979 по 2009 год скользящий средний показатель индекса SP 500 будут находиться в диапазоне -0,5% и 19.5% (9.5% ± 10%).
К сожалению, существует три основные причины, по которым данные об эффективности инвестиций могут не распространяться обычным образом. Во-первых, эффективность инвестиций, как правило, неравномерна, что означает, что распределение прибыли, как правило, асимметрично. В результате инвесторы, как правило, переживают периоды аномально высоких и низких показателей. Во-вторых, инвестиционная эффективность обычно обладает свойством, известным как эксцесс, что означает, что инвестиционная эффективность характеризуется аномально большим количеством положительных и/или отрицательных периодов эффективности. Взятые вместе, эти проблемы искажают внешний вид колоколообразной кривой и снижают точность стандартного отклонения как показателя риска.
В дополнение к перекосам и эксцессам, проблема, известная как гетероскедастичность, также вызывает беспокойство. Гетероскедастичность просто означает, что дисперсия выборочных данных об эффективности инвестиций не является постоянной с течением времени. В результате стандартное отклонение имеет тенденцию колебаться в зависимости от продолжительности периода времени, используемого для выполнения расчета, или периода времени, выбранного для выполнения расчета.
Подобно перекосу и эксцессу, последствия гетероскедастичности приведут к тому, что стандартное отклонение станет ненадежным показателем риска. Взятые в совокупности, эти три проблемы могут привести к неправильному пониманию инвесторами потенциальной волатильности своих инвестиций и привести к тому, что они потенциально пойдут на гораздо больший риск, чем ожидалось.
Упрощенный показатель волатильности
К счастью, существует гораздо более простой и точный способ измерения и изучения риска с помощью процесса, известного как исторический метод. Чтобы использовать этот метод, инвесторам просто нужно составить график исторических показателей своих инвестиций, создав диаграмму, известную как гистограмма.
Гистограмма — это диаграмма, на которой отображается доля наблюдений, попадающих во множество диапазонов категорий. Например, на приведенной ниже диаграмме были построены трехлетние скользящие средние показатели индекса SP 500, а горизонтальная ось представляет частоту, с которой индекс SP 500 показали доходность от 9% до 11,7%. С точки зрения показателей ниже или выше порогового значения, также можно определить, что индекс S#128077;
Источник: vc.ru
Функция Гаусса
В математике функция, график которой имеет форму колоколообразной кривой, называется функцией нормального распределения или функцией Гаусса. Она имеет следующий вид:
Функция Гаусса описывает предельное распределение результатов измерений величины x, истинное значение которой равно X. Причем при измерении величины x оказываются только случайные ошибки. Принято считать, что результаты измерений распределены нормально, если их предельное распределение описывается функцией Гаусса.
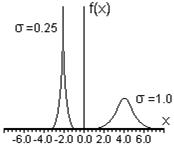
В формуле (3.2.1) величина σ является фиксированным параметром, который определяет ширину гауссовой кривой в точках перегиба. Малые значения σ приводят к распределению типа острого пика, которое соответствует более точным измерениям, в то время как большие значения σ дают широкое распределение, соответствующее измерениям с малой точностью.
На Рис.6 представлены два примера графиков функций Гаусса с различными значениями величин Х и . Видно, что величина σ в знаменателе предэкспоненциального множителя формулы (3.2.1) обеспечивает для более узкого распределения (малые ) большую высоту в точке x = X. Это обусловлено тем, что функция Гаусса нормирована, то есть для нее выполнено условие (3.1.6). Поэтому площадь под кривой, выражающей на графике функцию Гаусса, при любых значениях и X должна равняться единице.
Функция Гаусса отражает следующие предположения, лежащие в основе теории случайных погрешностей и подтверждаемые опытом:
1. Погрешности результатов наблюдений принимают непрерывный ряд значений.
2. При большом числе наблюдений одинаково часто встречаются погрешности одного значения, но разных знаков.
3. Частота появления погрешностей уменьшается с возрастанием их значений.
В случае распределения Гаусса среднее значение величины X определяется, согласно (3.1.5), по формуле:
Интеграл можно вычислить, что приведёт к следующему результату:
Отсюда можно сделать вывод: если результаты измерений распределены в соответствии с функцией Гаусса, то в случае бесконечно большого числа измерений среднее значение будет равно истинному значению , которое соответствует центру функции Гаусса.
Для дисперсии (3.1.9) в случае распределения Гаусса получим
Поскольку, согласно (3.1.10), корень из дисперсии есть стандартное отклонение, то
Следовательно: параметр ширины функции Гаусса есть стандартное отклонение, которое мы получили бы в случае бесконечно большего числа измерений.

Аальтернативная стоимость. Кривая производственных возможностей В экономике Буридании есть 100 ед. труда с производительностью 4 м ткани или 2 кг мяса.

Вычисление основной дактилоскопической формулы Вычислением основной дактоформулы обычно занимается следователь. Для этого все десять пальцев разбиваются на пять пар.
Расчетные и графические задания Равновесный объем — это объем, определяемый равенством спроса и предложения.
Кардиналистский и ординалистский подходы Кардиналистский (количественный подход) к анализу полезности основан на представлении о возможности измерения различных благ в условных единицах полезности.
Именные части речи, их общие и отличительные признаки Именные части речи в русском языке — это имя существительное, имя прилагательное, имя числительное, местоимение.
Интуитивное мышление Мышление — это психический процесс, обеспечивающий познание сущности предметов и явлений и самого субъекта.
Объект, субъект, предмет, цели и задачи управления персоналом Социальная система организации делится на две основные подсистемы: управляющую и управляемую.
Тема 2: Анатомо-топографическое строение полостей зубов верхней и нижней челюстей. Полость зуба — это сложная система разветвлений, имеющая разнообразную конфигурацию.
Виды и жанры театрализованных представлений Проживание бронируется и оплачивается слушателями самостоятельно.
Что происходит при встрече с близнецовым пламенем Если встреча с родственной душой может произойти достаточно спокойно – то встреча с близнецовым пламенем всегда подобна вспышке.
Источник: studopedia.info
Как я могу соответствовать гауссовой кривой в Python?
Мне присваивается массив, и когда я рисую его, я получаю гауссовскую форму с некоторым шумом. Я хочу соответствовать гауссову. Это то, что у меня уже есть, но когда я закладываю это, я не получаю гауссажа, вместо этого я просто получаю прямую линию. Я пробовал это много разных способов, и я просто не могу понять это.

P. Kaur 11 июнь 2017, в 06:34
Поделиться
Поделиться:
curve-fitting
4 ответа
Вы можете использовать fit из scipy.stats.norm следующим образом:
import numpy as np from scipy.stats import norm import matplotlib.pyplot as plt data = np.random.normal(loc=5.0, scale=2.0, size=1000) mean,std=norm.fit(data)
norm.fit пытается соответствовать параметрам нормального распределения на основе данных. И действительно, в приведенном выше примере mean составляет приблизительно 2 и std составляет приблизительно 5. Чтобы сделать это, вы можете сделать:

Синие квадраты — это гистограмма ваших данных, а зеленая линия — гауссовская с установленными параметрами.
Miriam Farber 11 июнь 2017, в 05:34
Поделиться
Вы можете найти lmfit полезным для этого. Он имеет встроенные методы для гауссова фитинга и множество удобных опций для проблем с подгонкой. См
https://lmfit.github.io/lmfit-py/builtin_models.html#example-1-fit-peaked-data-to-gaussian-lorentzian-and-voigt-profiles
M Newville 12 июнь 2017, в 04:11
Поделиться
Этот метод хорошо работал для того, чтобы дать мне различные параметры, такие как сигма и среднее значение, но как я могу построить подходящий гассиан на моих исходных данных?
P. Kaur 12 июнь 2017, в 14:43
с out = model.fit(. ) , массив наиболее подходящей модели хранится в out.best_fit — он должен быть готов для построения графиков с данными. В папке docs и examples есть много проработанных примеров сценариев, которые включают в себя прорисовку.
M Newville 15 июнь 2017, в 01:49
Существует множество способов привязки gaussian-функции к набору данных. Я часто использую астропию при подгонке данных, поэтому я хотел добавить это в качестве дополнительного ответа.
Я использую некоторый набор данных, который должен имитировать гауссовский шум с некоторым шумом:
import numpy as np from astropy import modeling m = modeling.models.Gaussian1D(amplitude=10, mean=30, stddev=5) x = np.linspace(0, 100, 2000) data = m(x) data = data + np.sqrt(data) * np.random.random(x.size) — 0.5 data -= data.min() plt.plot(x, data)

Тогда установка на самом деле довольно проста, вы указываете модель, которую хотите поместить в данные и слесарь:
fitter = modeling.fitting.LevMarLSQFitter() model = modeling.models.Gaussian1D() # depending on the data you need to give some initial values fitted_model = fitter(model, x, data)
plt.plot(x, data) plt.plot(x, fitted_model(x))

Однако вы также можете использовать только Scipy, но вы должны сами определить функцию:
from scipy import optimize def gaussian(x, amplitude, mean, stddev): return amplitude * np.exp(-((x — mean) / 4 / stddev)**2) popt, _ = optimize.curve_fit(gaussian, x, data)
Это возвращает оптимальные аргументы для соответствия, и вы можете построить его так:
plt.plot(x, data) plt.plot(x, gaussian(x, *popt))

MSeifert 06 янв. 2018, в 20:22
Поделиться
Вы также можете поместить функцию Гаусса с помощью функции curve_fit из scipy.optimize(), где вы можете определить свою собственную настраиваемую функцию. Здесь я приведу пример гауссовой подгонки. Например, если у вас есть два массива x и y .
from scipy.optimize import curve_fit from scipy import asarray as ar,exp x = ar(range(10)) y = ar([0,1,2,3,4,5,4,3,2,1]) n = len(x) #the number of data mean = sum(x*y)/n #note this correction sigma = sum(y*(x-mean)**2)/n #note this correction def gaus(x,a,x0,sigma): return a*exp(-(x-x0)**2/(2*sigma**2)) popt,pcov = curve_fit(gaus,x,y,p0=[1,mean,sigma]) plt.plot(x,y,’b+:’,label=’data’) plt.plot(x,gaus(x,*popt),’ro:’,label=’fit’) plt.legend()
Функция curve_fit должна вызываться с тремя аргументами: функция, которую вы хотите поместить (gaus() в этом случае), значения независимой переменной (в нашем случае x) и значения переменной depenedent (в нашем случае y). Функция curve_fit funtion возвращает массив с оптимальными параметрами (в смысле наименьших квадратов) и второй массив, содержащий ковариацию оптимальных параметров (подробнее об этом позже).
Ниже приведен результат соответствия.
Источник: overcoder.net