Привет, я руководитель SEO-отдела в компании TRINET.Group. Если на сайте падает трафик, возможно, запрещена индексация для поисковых систем. Причина в файле robots.txt. Если вовремя обнаружить проблему и настроить его работу правильно, индексация веб-страниц восстановится.
В этом видео я рассказываю, как robots.txt влияет на индексацию
В этой статье рассмотрим:
- Что такое robots.txt?
- Как его правильно настроить?
- Какие сервисы использовать для проверок robots.txt?
- Почему не стоит запрещать пагинацию?
Что такое robots.txt
Справка: robots.txt — это файл в корневом каталоге, который отвечает за то, чтобы сайт был открыт для индексации и сканирования страницы или ее элементов поисковыми системами.

Robots.txt. Для чего он нужен и как им пользоваться?
Пример файла robots.txt
Прежде чем зайти на сайт, поисковая система обращается к файлу robots.txt и индексирует директивы — правила, которые запрещают индексацию страниц. Например, указан «User-agent» — обязательная директива, где указано, для какого робота указаны правила. Если стоит «*» (звездочка), это означает руководство для всех роботов. Можно создать персональные правила для ботов Яндекса (User-agent: Yandex) или Google (User-agent: Googlebot).
Файл передает один из трех вариантов разрешений:
- Частичный допуск — сканирование отдельных элементов. Запрещает индексацию данных, которые нельзя допускать в выдачу — формы с личными данными пользователей, дублированные страницы, неуникальные изображения и др.
- Полный доступ — разрешено сканировать все.
- Полный запрет — нельзя сканировать ничего. Часто такое ограничение применяется при размещении нового сайта, чтобы он был закрыт для посещения, пока ведется его разработка, наполнение и проверка работы.
Часто разработчики при запуске нового сайта забывают обновить этот файл и открыть сайт для индексации. И почему-то делают это по пятницам, не предупреждая никого. Таким образом, страницы нового сайта автоматически будут закрыты на выходные, трафик и продажи упадут. Страницы могут вылетать из индекса — обычно до 2 недель.
Если это быстро заметить, после исправления robots.txt индексация восстановится и позиции могут вернуться обратно. Если до открытия индексации пройдет больше недели, могут быть более негативные последствия.
Файл robots.txt необходим, и его важно корректно настраивать. Например, вам не нужно, чтобы поисковая система просканировала какие-то дублированные изображения или вы хотите скрыть от посетителей раздел, предназначенный только для сотрудников.
Главное предназначение robots.txt в SEO — закрытие дублей. Например, есть технические дубли страниц сортировки, фильтрации, UTM-метки, которые генерирует система управления сайтом CMS. От таких страниц в индексе необходимо избавиться, закрыть их от индексации.
Как создать robots.txt и настроить его работу
Это обычный текстовый файл, который создается в блокноте. Указываются User-agent с помощью значка «звездочка» и ниже прописываются правила.
Существует несколько способов, как создать robots.txt:
Справка: Файл robots.txt создается через блокнот и сохраняется в формате «.txt». Учитывайте ограничение по размеру до 32 Кб на индексацию поисковой системой Яндекс.
Для формирования файла в CMS есть свои плагины. Классический вариант размещения — публикация через файловый менеджер или FTP-соединение с перезаписыванием файла. Обязательно проверьте результат. Возможно кэширование результатов — в таком случае обновите кэш браузера. Если хочется внедрить изменения и узнать, как будет работать страница, закроется ли она от индексации, не запретили ли лишнего, используйте сервисы проверки от Яндекса.
Основные директивы robots.txt
Инструкции для поисковых роботов указываются с помощью символов и текста. Важно разобраться, какие директивы за что отвечают. Есть стандартные формулировки правил. Вот несколько примеров директив:
- Disallow — запрет сканирования. Ставится двоеточие и внутри знаков «/» пишется название раздела, который нельзя сканировать. Disallow: /admin/ — будет запрещена индексация содержимого указанного раздела.
- Allow — разрешающая директива. По умолчанию все, что не запрещено, то разрешено.
- «$» — указывает на конец строки, например Disallow: /poly/$, папку индексировать нельзя, а ее содержимое можно.
- Sitemap — указывает путь к карте сайта для ускорения индексации.
C помощью специальных платных программ можно удобно изучать каждую страницу на предмет доступности для индексации.
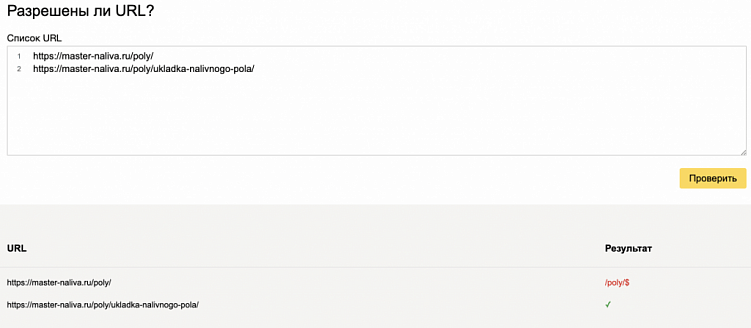
Пример проверки в Яндекс Вебмастер
Почему не стоит запрещать пагинацию
Справка: пагинация — это разделение контента на сайте на отдельные страницы. Часто применяется в каталогах интернет-магазинов.
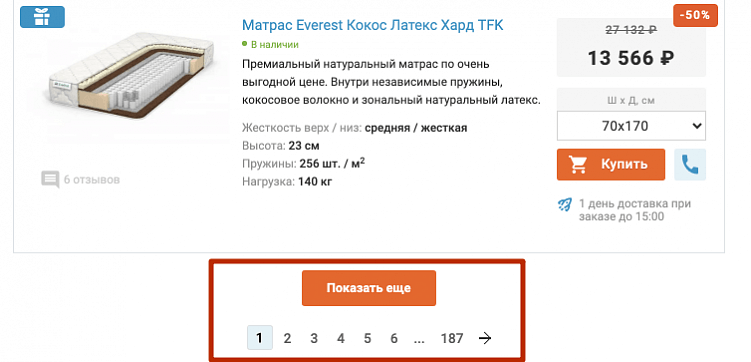
Пример страниц пагинации
Например, в одном из листингов представлены кольца — 1000 видов. Если разместить все в одном разделе, скорость загрузки страницы будет крайне низкой. Чтобы не выводить 1000 позиций в одном листинге, его разбивают на подстраницы для удобства клиентов и поисковых роботов.
Практические решения закрытия сайта или его части от индексации

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Зачем закрывают сайт или какие-то его части от индексации поисковых систем? Ответов несколько
- Нужно скрыть от общего доступа какую то секретную информацию.
- В целях создания релевантного контента: бывают случаи, когда хочется донести до пользователей больше информации, но она размывает текстовую релевантность.
- Закрыть дублированный контент.
- Скрыть мусорную информацию: поисковые системы очень не любят контент, который не несет или имеет устаревший смысл, например, календарь в афише.
Вся статья будет неким хелпом по закрытию от индексации для различных ситуаций:
Решение: запрет на индексацию сайта с помощью robots.txt
Создаем текстовый файл с названием robots, получаем robots.txt.
Копируем туда этот код
User-agent: * Disallow: /
Полученный файл с помощью FTP заливаем в корень сайта.
Если нужно закрыть индексацию сайта только от Яндекс:
User-agent: Yandex Disallow: /
Если же скрываем сайт только от Google, то код такой:
User-agent: Googlebot Disallow: /
Закрыть сайт от индексации в файле .htaccess
Способ первый
В файл .htaccess вписываем следующий код:
SetEnvIfNoCase User-Agent «^Googlebot» search_bot SetEnvIfNoCase User-Agent «^Yandex» search_bot SetEnvIfNoCase User-Agent «^Yahoo» search_bot SetEnvIfNoCase User-Agent «^Aport» search_bot SetEnvIfNoCase User-Agent «^msnbot» search_bot SetEnvIfNoCase User-Agent «^spider» search_bot SetEnvIfNoCase User-Agent «^Robot» search_bot SetEnvIfNoCase User-Agent «^php» search_bot SetEnvIfNoCase User-Agent «^Mail» search_bot SetEnvIfNoCase User-Agent «^bot» search_bot SetEnvIfNoCase User-Agent «^igdeSpyder» search_bot SetEnvIfNoCase User-Agent «^Snapbot» search_bot SetEnvIfNoCase User-Agent «^WordPress» search_bot SetEnvIfNoCase User-Agent «^BlogPulseLive» search_bot SetEnvIfNoCase User-Agent «^Parser» search_bot
Каждая строчка для отдельной поисковой системы
Способ второй и третий
Для всех страниц на сайте подойдет любой из вариантов — в файле .htaccess прописываем любой из ответов сервера для страницы, которую нужно закрыть.
- Ответ сервера — 403 Доступ к ресурсу запрещен -код 403 Forbidden
- Ответ сервера — 410 Ресурс недоступен — окончательно удален
Способ четвертый
Запретить индексацию с помощью доступа к сайту только по паролю
В файл .htaccess, добавляем такой код:
AuthType Basic AuthName «Password Protected Area» AuthUserFile /home/user/www-auth/.htpasswd Require valid-user
home/user/www-auth/.htpasswd — файл с паролем — пароль задаете Вы сами.
Авторизацию уже увидите, но она пока еще не работает
Теперь необходимо добавить пользователя в файл паролей:
htpasswd -c /home/user/www-auth/.htpasswd USERNAME
USERNAME это имя пользователя для авторизации. Укажите свой вариант.
Задача: закрыть от индексации поддомен
Поддомен для поисковых систем является отдельным сайтом, из чего следует, что для него подходят все варианты того, как закрыть от индексации сайт.
Закрываем блок на сайте от индекса
Довольно часто требуется закрыть от индексации определенный блок: меню, счетчик, текст или какой-нибудь код.
Когда был популярен в основном Яндекс, а Google все само как то в топ выходило, все использовали вариант Тег «noindex»
Все что угодно тут — ссылки или текст или код
Но потом Яндекс все чаще и чаще стал не обращать внимания на такой технический прием, а Google вообще не понимает такой комбинации и все стали использовать другую схему для скрытия от индексации части текста на странице — с помощью javascript:
Текст или любой блок — кодируется в javascript , а потом сам скрипт закрывается от индексации в robots.txt
Как это реализовать?
- Файл BASE64.js для декодирования того, что нужно скрыть.
- Алгоритм SEOhide.js.
- Jquery.
- Robots.txt (чтобы скрыть от индексации сам файл SEOhide.js)
- HTML код
BASE64.js. Здесь я его приводить не буду, в данном контексте он нам не так интересен.
; var seoHrefs = ; var $elements = $(«[data-key]»); for(var i = 0, count = $elements.length; i < count; i++) < var $element = $elements.eq(i); var key = $element.data(«key»); switch($element.data(«type»)) < case «href»: $element.attr(«href», Base64.decode(seoHrefs[key])); break; case «content»: $element.replaceWith(Base64.decode(seoContent[key])); break; >> $(document).trigger( «renderpage.finish»); >);
Переменные seoContent и seoHrefs. В одну записываем html код, в другую ссылки.
- de96dd3df7c0a4db1f8d5612546acdbb — это идентификатор, по которому будет осуществляться замена.
- 0JHQu9C+0LMgU0VPINC80LDRgNC60LXRgtC+0LvQvtCz0LAgLSDQn9Cw0LLQu9CwINCc0LDQu9GM0YbQtdCy0LAu— html, который будет отображаться для объявленного идентификатора.
И сам HTML файл:
В robots.txt обязательно скрываем от индексации файл SEOhide.js.
Универсальный вариант скрытия картинок от индексации
К примеру, вы используете на сайте картинки, но они не являются оригинальными. Есть страх, что поисковые системы воспримут их негативно.
Код элемента, в данном случае ссылки, на странице, будет такой:
Скрипт, который будет обрабатывать элемент:
Задача: закрыть внешние или внутренние ссылки от индексации
Обычно это делают для того, чтобы не передавать вес другим сайтам или при перелинковке уменьшить уходящий вес текущей страницы.
Создаем файл transfers.js
Эту часть кода вставляем в transfers.js
function goPage(sPage)
Этот файл, размещаем в соответствующей папке (как в примере «js») и на странице в head вставляем код:
А это и есть сама ссылка, которую нужно скрыть от индексации:
Как закрыть от индексации страницу на сайте
- 1 Вариант — в robots.txt
Disallow: /url-stranica.html
- 2 Вариант — закрыть страницу в метегах — это наиболее правильный вариант
— закроет страницу от индексации
- 3 Вариант — запретить индексацию через ответ сервера
Задача, чтобы ответ сервера для поисковых систем был
404 — ошибка страницы
410 — страница удаленна
Добавить в файл .htaccess:
ErrorDocument 404 http://site.ru/404
это серый метод, использовать в крайних мерах
Как закрыть от индексации сразу весь раздел на проекте
1 Вариант реализовать это с помощь robots.txt
User-agent: * Disallow: /razdel
Также подойдут варианты, которые используются при скрытии страницы от индекса, только в данном случае это должно распространятся на все страницы раздела — конечно же если это позволяет сделать автоматически
- Ответ сервера для всех страниц раздела
- Вариант с метатегами к каждой странице
Это все можно реализовать программно, а не в ручную прописывать к каждой странице — трудозатраты — одинаковые.
Конечно же проще всего это прописать запрет в robots, но наша практика показывает, что это не 100% вариант и поисковые системы бывает игнорируют запреты.
Закрываем папку от индексации
В данном случае под папкой имеется ввиду не раздел,а именно папка в которой находят файлы, которые стоит скрыть от поисковых систем — это или картинки или документы
Единственный вариант для отдельной папки это реализация через robots.txt
User-agent: * Disallow: /folder/
Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
1 Вариант — и самый правильный, чтобы их не было — нужно физически от них избавиться т.е при любой ситуации кроме оригинальной страницы — должна показываться 404 ответ сервера
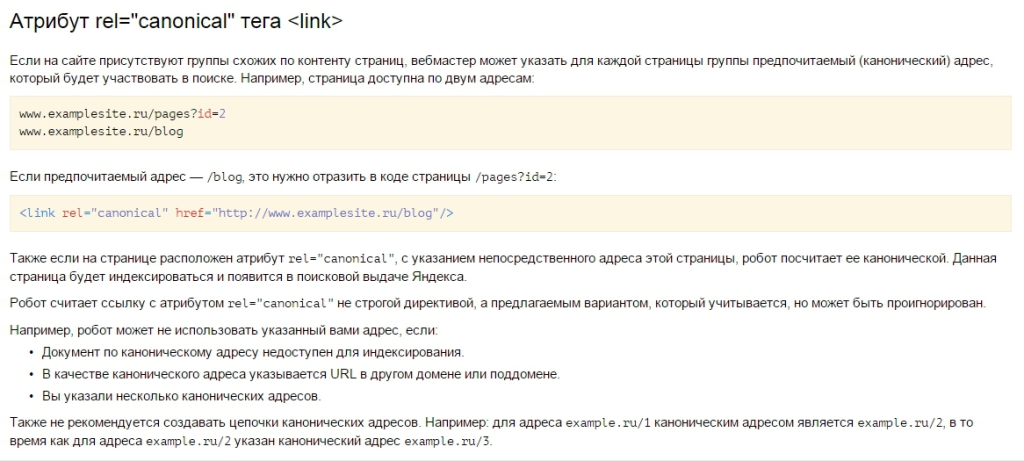
2 Вариант — использовать Атрибут rel=»canonical» — он и является самым верным. Так как помимо того, что не позволяет индексироваться дублям, так еще и передает вес с дублей на оригиналы
Ну странице дубля к коде необходимо указать
3 Вариант избавиться от индексации дублей — это все дублирующие страницы склеить с оригиналами 301 редиректом через файл .htaccess
4 Вариант — метатеги на каждой странице дублей
5 Вариант — все тот же robots
Если что то упустили, будем рады любым дополнениям в комментариях.
Может пригодиться: продвижение сайта по трафику в Москве — готовы ли вы к приливу посетителей?
Рассказать о статье:

Получите профессиональный взгляд со стороны на свой проект
Специалисты студии SEMANTICA проведут комплексный анализ сайта по следующему плану:
– Технический аудит.
– Оптимизация.
– Коммерческие факторы.
– Внешние факторы.
Проверка robots.txt на ошибки

В одной из прошлых статей мы с вами подробно рассмотрели, как создать файл robots.txt на примере сайта созданного на WordPress.
Вот ссылка на предыдущую статью: Файл robots.txt для сайта WordPress
В этой статье я хотела бы рассмотреть, как осуществить для robots.txt проверку в поисковых системах Яндекс и Google.
Навигация по статье:
- Проверка в Яндекс
- Проверка в Google

Проверка в Яндекс
В яндексе для robots.txt проверка происходит следующим образом:
-
1. Заходим на сервис Яндекс.Вебмастер (https://webmaster.yandex.ru), проходим авторизацию и в верхней панели слева, в раскрывающемся списке, выбираем сайт для которого нужно провести проверку.
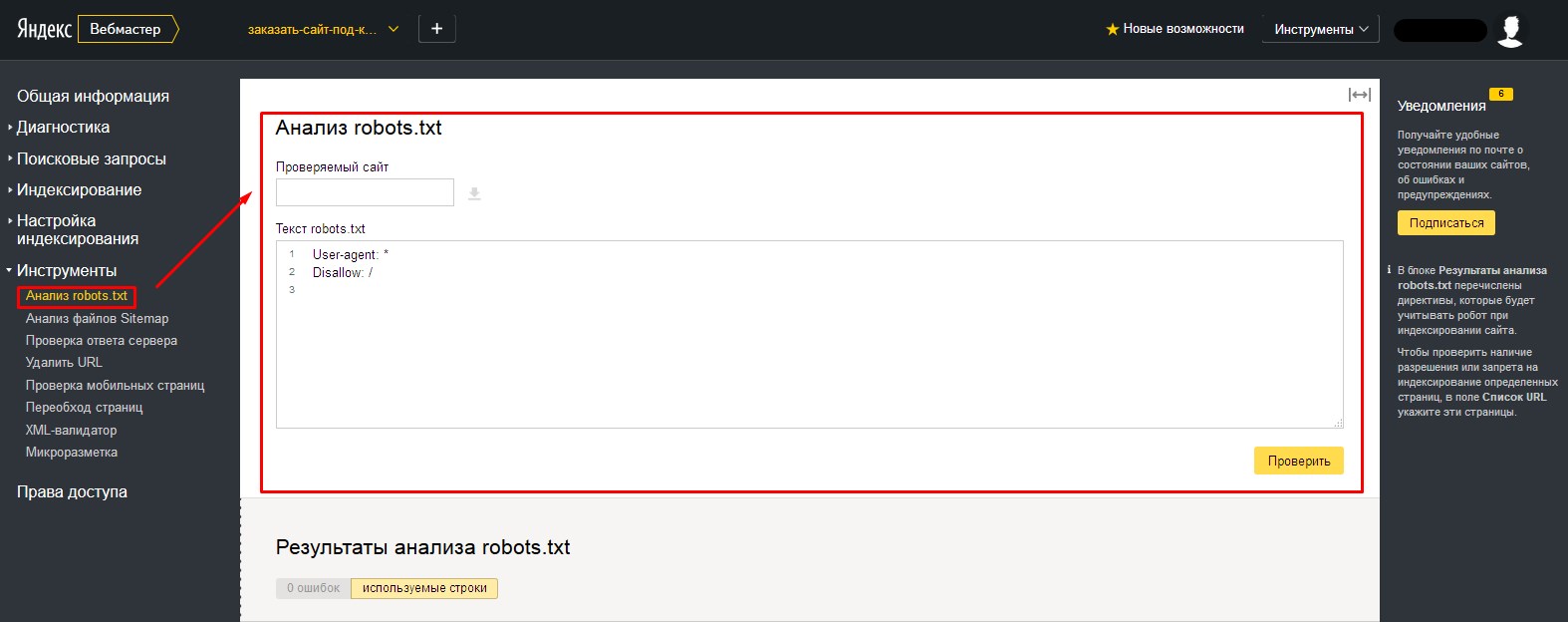

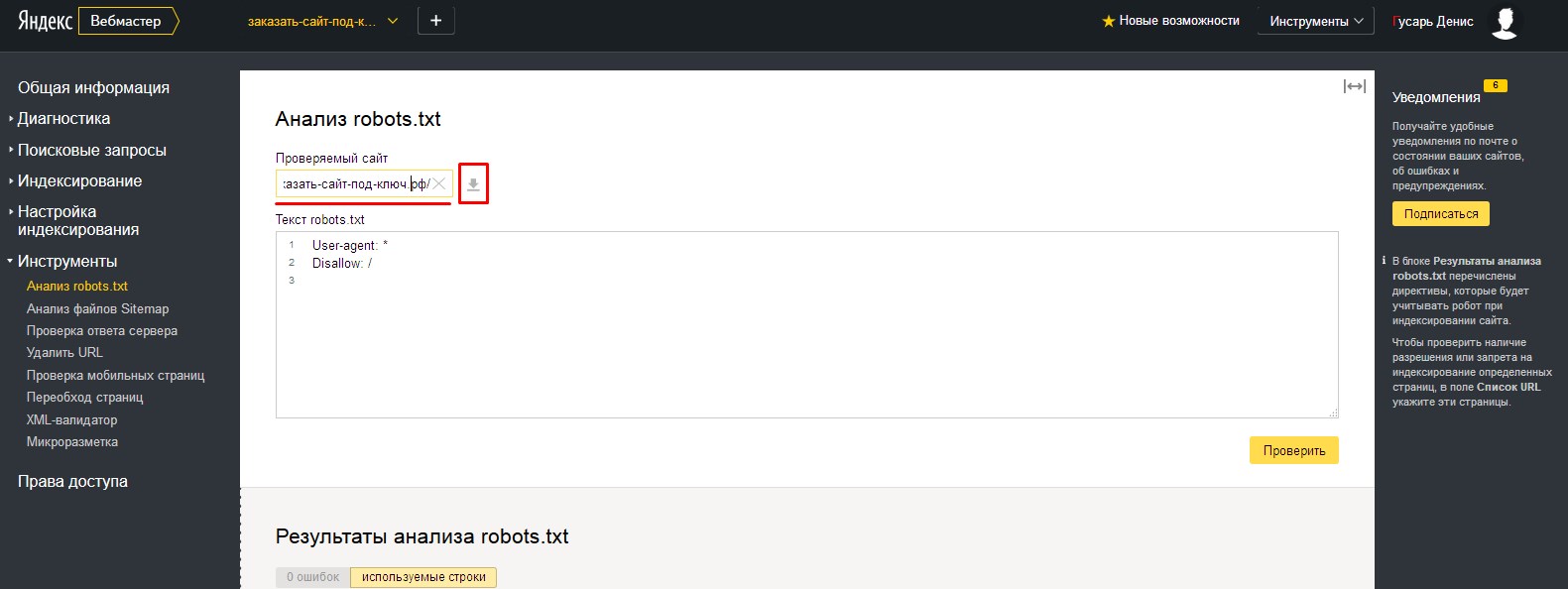
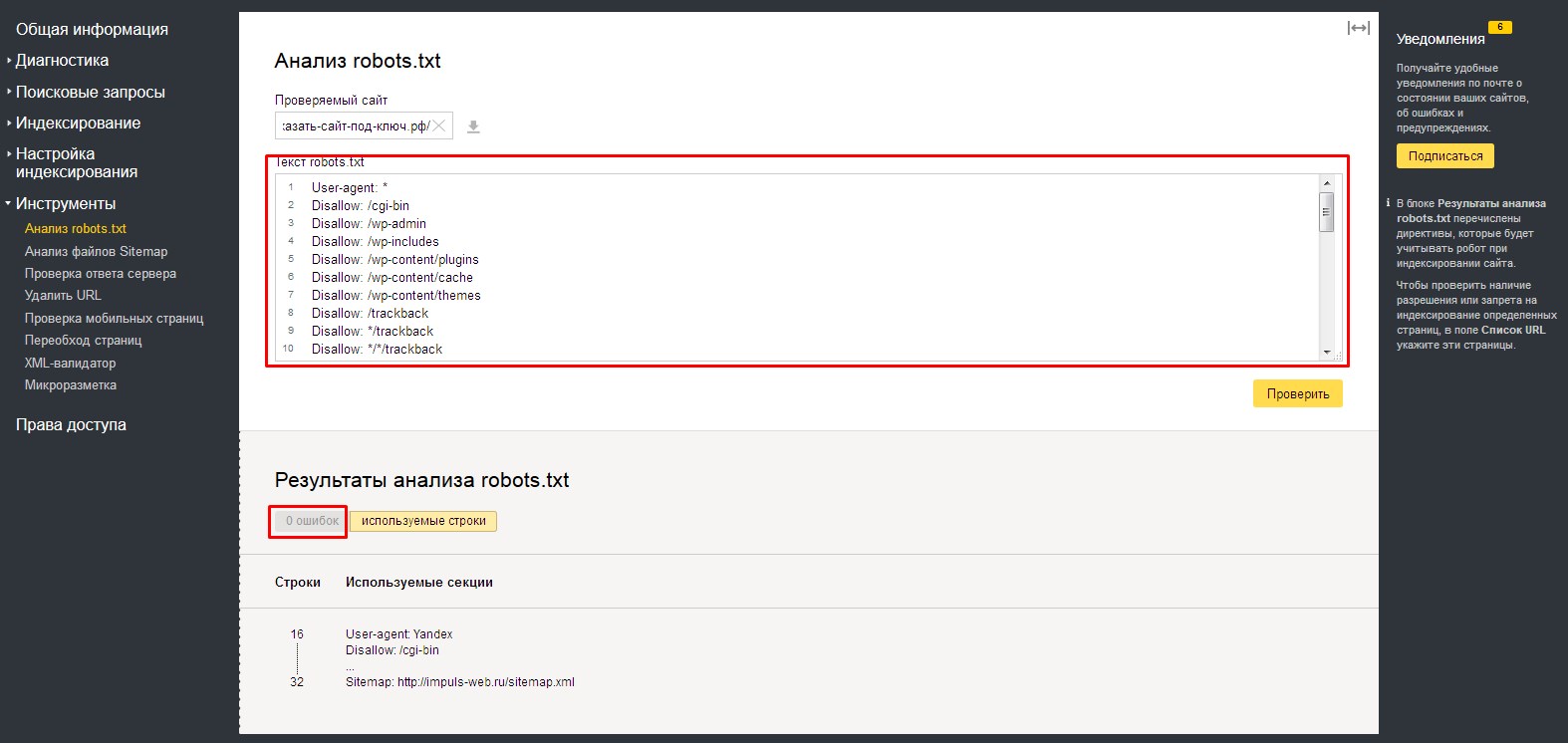
Внизу, в табличке «Результаты анализа robots.txt», вы можете просмотреть количество ошибок в файле.
Проверка в Google
В Google Search Console для robots.txt проверка делается похожим образом:
-
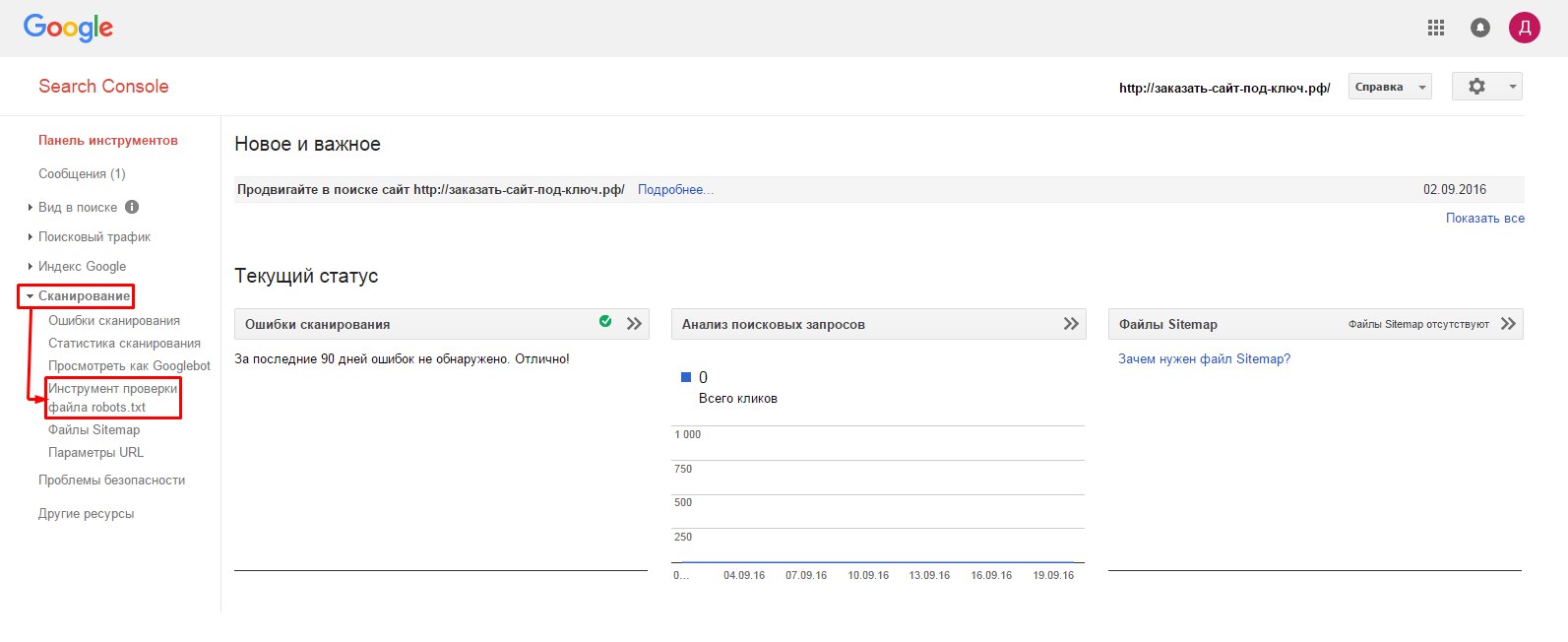
1. Заходим на главную страницу сервиса Search Console (//www.google.com/webmasters/tools/dashboard), проходим авторизацию и переходим в раздел «Сканирование» =>«Инструмент проверки файла robots.txt»
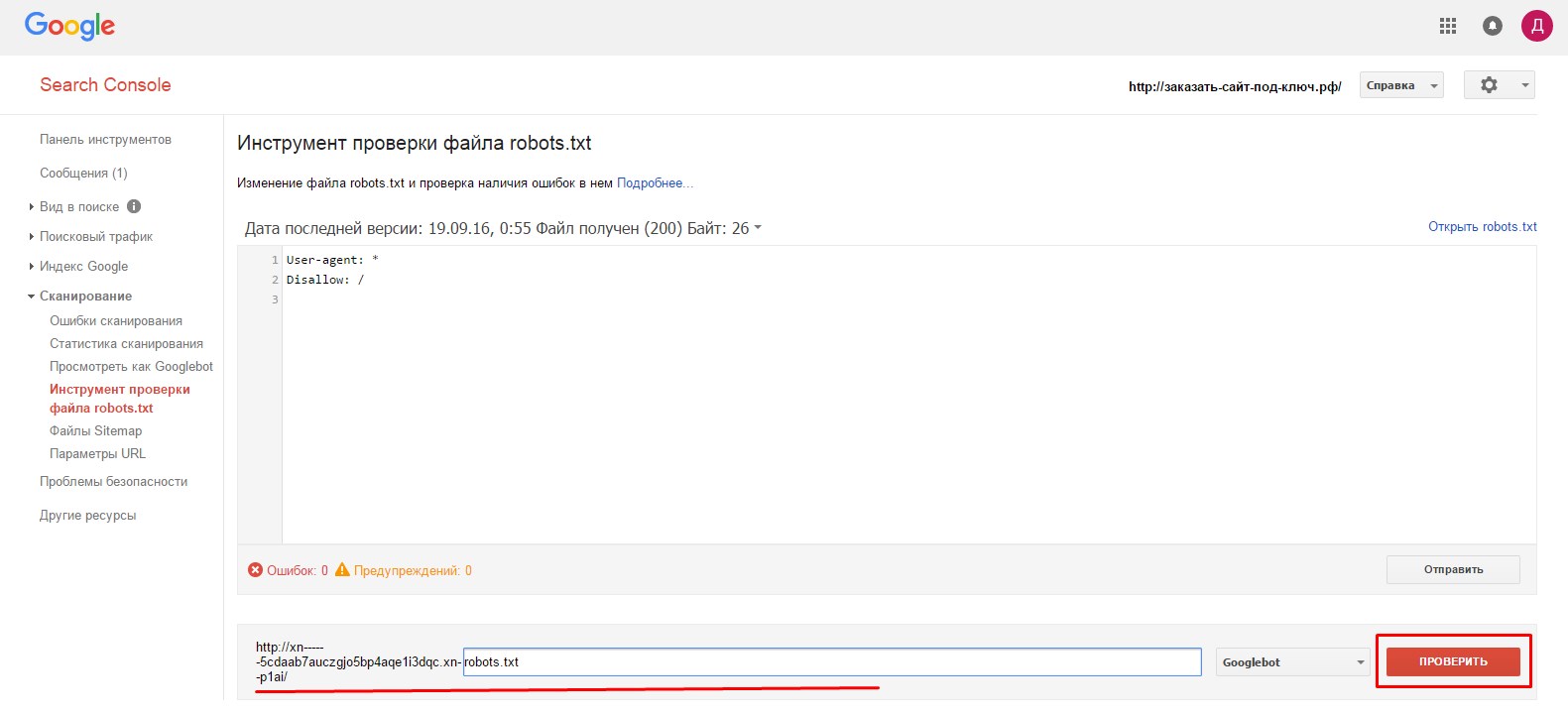

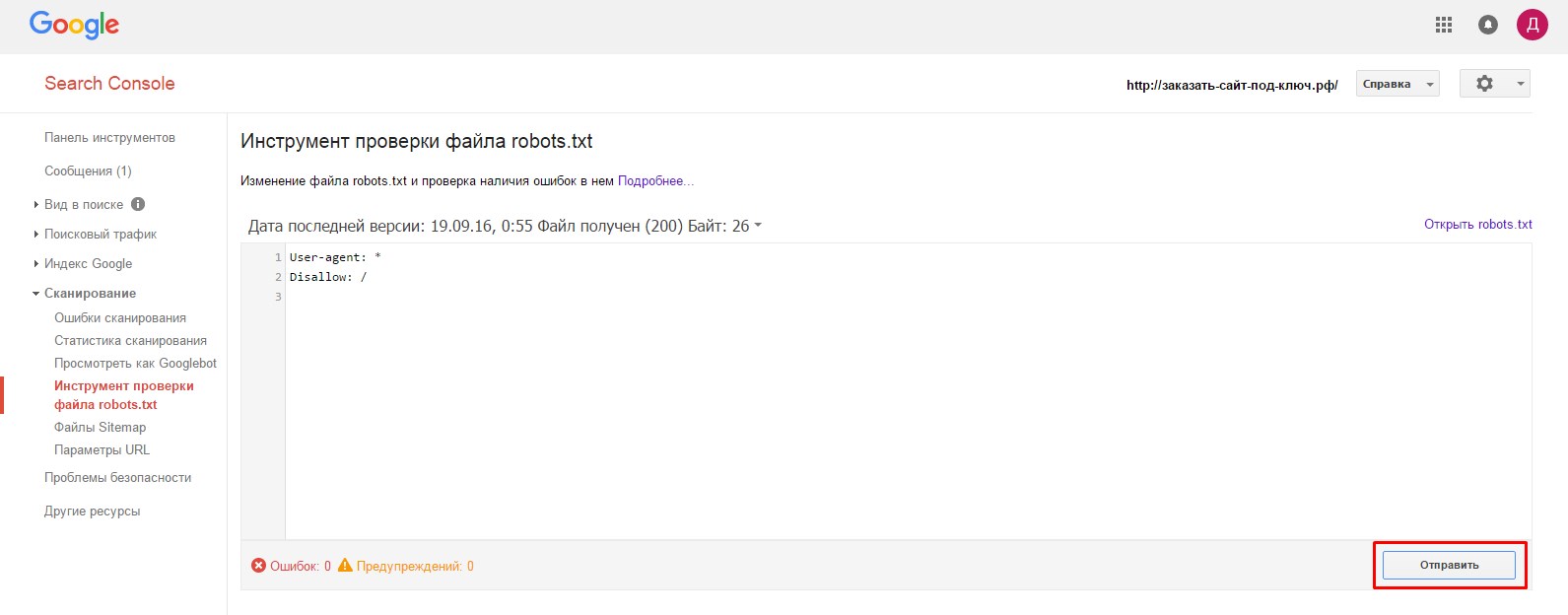
В открывшемся окне нужно нажить на нижнюю кнопку «Отправить»:
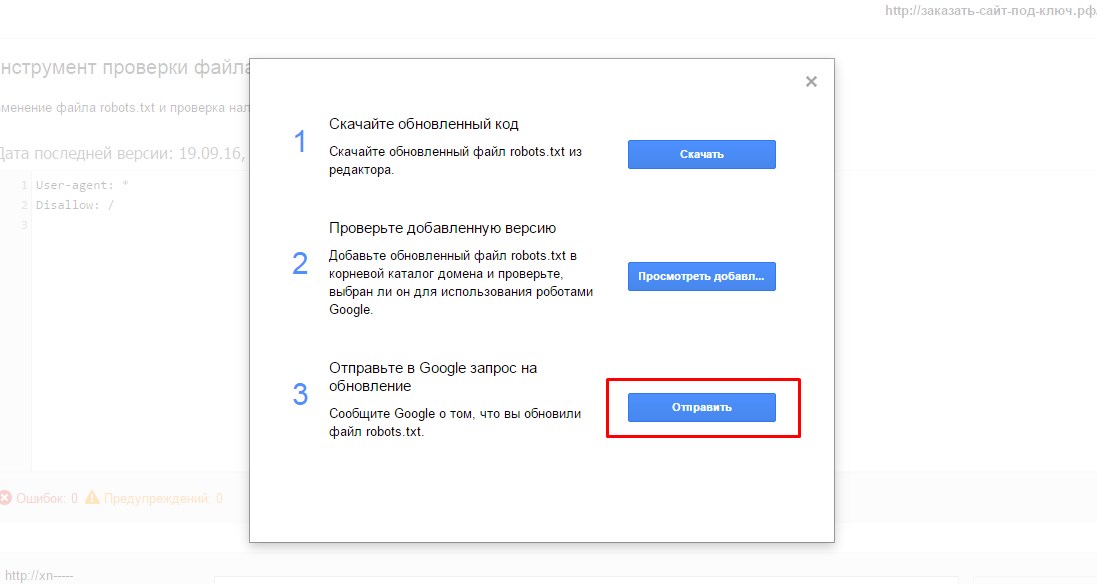

Количество ошибок и предупреждений можно увидеть в нижней части окна.
Как видите, для robots.txt проверка проводится достаточно быстро. Если после проверки у вас найдут какие-то несоответствия, то нужно будет их исправить и повторить процедуру загрузки и проверки файла в той же последовательности.

А на этом у меня сегодня все. Надеюсь, моя статья будет для вас полезна. Думаю, у вас не должно возникнут каких-то сложностей в процессе создания и загрузки файла robots.txt, но если что – пишите мне через форму комментариев. Желаю вам успешной проверки! До встречи в следующих статьях!
С уважением Юлия Гусарь
Источник: impuls-web.ru